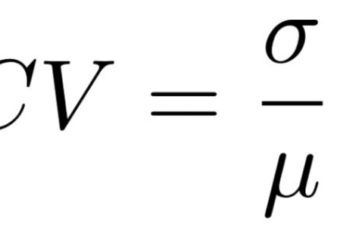Statistiques non paramétriques
Les statistiques non paramétriques font référence à une méthode statistique dans laquelle les données ne sont pas nécessaires pour correspondre à une distribution normale. Les statistiques non paramétriques utilisent des données souvent ordinales, ce qui signifie qu’elles ne reposent pas sur des nombres, mais plutôt sur un classement ou un ordre de tri. Par exemple, une enquête transmettant les préférences des consommateurs allant de semblable à ne pas aimer serait considérée comme des données ordinales.
Les statistiques non paramétriques incluent les statistiques descriptives non paramétriques , les modèles statistiques, l’inférence et les tests statistiques. La structure du modèle des modèles non paramétriques n’est pas spécifiée a priori mais est plutôt déterminée à partir des données. Le terme non paramétrique ne signifie pas que ces modèles manquent complètement de paramètres, mais plutôt que le nombre et la nature des paramètres sont flexibles et non fixés à l’avance. Un histogramme est un exemple d’estimation non paramétrique d’une distribution de probabilité.
Comprendre les statistiques non paramétriques
En statistique, la statistique paramétrique comprend des paramètres tels que la moyenne, la médiane, l’écart type, la variance, etc. Cette forme de statistique utilise les données observées pour estimer les paramètres de la distribution. Selon les statistiques paramétriques, les données sont supposées correspondre à une distribution normale avec des paramètres inconnus μ (moyenne de la population) et σ 2 (variance de la population), qui sont ensuite estimés en utilisant la moyenne et la variance de l’échantillon.
Les statistiques non paramétriques ne font aucune hypothèse sur la taille de l’échantillon ou si les données observées sont quantitatives.
Les statistiques non paramétriques ne supposent pas que les données sont tirées d’une distribution normale. Au lieu de cela, la forme de la distribution est estimée sous cette forme de mesure statistique. Bien qu’il existe de nombreuses situations dans lesquelles une distribution normale peut être supposée, il existe également certains scénarios dans lesquels il ne sera pas possible de déterminer si les données seront normalement distribuées.
Exemples de statistiques non paramétriques
Dans le premier exemple, considérons qu’un chercheur qui souhaite une estimation du nombre de bébés nés avec des yeux bruns en Amérique du Nord peut décider de prélever un échantillon de 150 000 bébés et d’effectuer une analyse sur l’ensemble de données. La mesure qu’ils dérivent sera utilisée comme une estimation de l’ensemble de la population de bébés aux yeux bruns nés l’année suivante.
Pour un deuxième exemple, considérons un autre chercheur qui veut savoir si se coucher tôt ou tard est lié à la fréquence à laquelle on tombe malade. En supposant que l’échantillon est choisi au hasard dans la population, la distribution de la taille de l’ échantillon de la fréquence des maladies peut être supposée normale. Cependant, une expérience qui mesure la résistance du corps humain à une souche de bactéries ne peut pas être supposée avoir une distribution normale.
En effet, un échantillon de données sélectionnées au hasard peut être une résistance à la souche. En revanche, si le chercheur prend en compte des facteurs tels que la constitution génétique et l’origine ethnique, il peut constater qu’une taille d’échantillon sélectionnée en utilisant ces caractéristiques peut ne pas être résistante à la souche. Par conséquent, on ne peut pas supposer une distribution normale.
Cette méthode est utile lorsque les données n’ont pas d’interprétation numérique claire et est préférable de l’utiliser avec des données qui ont un classement en quelque sorte. Par exemple, un test d’évaluation de la personnalité peut avoir un classement de ses paramètres défini comme fortement en désaccord indifférent, d’accord et fortement d’accord. Dans ce cas, des méthodes non paramétriques doivent être utilisées.
Considérations particulières
Les statistiques non paramétriques ont gagné en appréciation en raison de leur facilité d’utilisation. À mesure que le besoin de paramètres est supprimé, les données deviennent plus applicables à une plus grande variété de tests. Ce type de statistiques peut être utilisé sans la moyenne, la taille de l’échantillon, l’écart-type ou l’estimation de tout autre paramètre connexe lorsqu’aucune de ces informations n’est disponible.
Étant donné que les statistiques non paramétriques font moins d’hypothèses sur les données d’échantillon, son application est plus large que les statistiques paramétriques. Dans les cas où les tests paramétriques sont plus appropriés, les méthodes non paramétriques seront moins efficaces. En effet, les résultats obtenus à partir de statistiques non paramétriques ont un degré de confiance plus faible que si les résultats étaient obtenus à l’aide de statistiques paramétriques.
Retenons
- Les statistiques non paramétriques sont faciles à utiliser mais n’offrent pas la précision exacte d’autres modèles statistiques.
- Ce type d’analyse convient mieux lorsque l’on considère l’ordre de quelque chose, où même si les données numériques changent, les résultats resteront probablement les mêmes.